初学正则表达式
正则表达式?
正则表达式是一种被用于从文本中检索符合某些特定模式的文本, 英文为 "Regular Expression", 缩写 "regex" 或者 "regexp".
正则表达式可以很简单的实现比较复杂的字符串匹配逻辑, 来快速地对用户输入施加限制条件.
在日常的文本编辑中, 正则表达式还可以快速的实现复杂的替换操作, 使得文本编辑省时省力.
正则表达式依赖于所处的环境, JavaScript, C#, Java, C++ 等不同的开发语言中以及 VSCode 等不同的文本编辑器下, 正则表达式的匹配规则会有一些细微的差别.
元字符不能写在字符集合
[ ]的里面.[ ]中的元字符全部会变为普通字符.
普通元字符
| 元字符 | 描述 |
|---|---|
| . | 表示一个除换行符以外的任意字符 |
| () | 字符组, 占位长度和字符串长度一致, 匹配其中的字符串或者逻辑 |
| [ ] | 字符集合, 默认占位长度为 1, 匹配集合中的任意一个字符, 可以使用范围符 - 来表示范围, 如: 0-9, a-z, A-Z 等 |
| [^ ] | 否定字符集合, 默认占位长度为 1, 匹配集合中的所有字符以外的任意一个字符 |
| | | 逻辑或 |
| \ | 转义符 |
字符集
[注意] 字符集名称(大小写敏感), \w 和 \W 的含义完全相反.
| 转义符 | 描述 |
|---|---|
| \f | 匹配一个换页符 |
| \n | 匹配一个换行符 |
| \r | 匹配一个回车符 |
| \t | 匹配一个制表符 |
| \v | 匹配一个垂直制表符 |
| \w | 匹配所有字母和数字的字符, 某些环境下也会匹配汉字 |
| \W | 匹配非字母和数字的字符, 某些环境下汉字也会排除 |
| \d | 匹配数字: [0-9] |
| \D | 匹配非数字: [^ 0-9] |
| \s | 匹配任何空白字符, 包括空格, 制表符, 换页符等 |
| \S | 匹配非空格符 |
次数限定符
写在一个特定的字符或者字符组 () 的后面, 控制字符或者字符组的出现次数.
| 次数限定符 | 描述 |
|---|---|
| * | 匹配前面的子表达式 0 次或多次 |
| + | 匹配前面的子表达式 1 次或多次 |
| ? | 匹配前面的子表达式 0 次或 1 次, 或指明一个非贪婪限定符 |
| {n} | 花括号, 匹配前面字符或字符组 n 次 |
| {n,} | 花括号, 匹配前面字符或字符组至少 n 次 |
| {n,m} | 花括号, 匹配前面字符或字符组至少 n 次, 但是不超过 m 次 |
定位符
定位符表示字符所处的位置.
| 定位符 | 描述 |
|---|---|
| ^ | 表示行的开始 |
| $ | 表示行的结束 |
| \b | 匹配一个单词边界 |
| \B | 非单词边界匹配 |
前后缀逻辑 (断言)
Q1: 匹配字符串中以全角美元符开头的 '12000.00'
12000.00 ¥12000.00 $12000.00
Q2: 匹配字符串中以全角美元符结尾的 '12000.00'
12000.00 12000.00¥ 12000.00$
上面的两个问题, 就可以通过在正则表达式中添加前后缀逻辑来解决. '前后缀逻辑' 是我自己起的名字, 方便自己记忆, 但是有的文章中叫作 "断言", 有的文章中叫 "预匹配", 我都感觉好别扭啊!
[注] 前后缀逻辑必须写在字符组 () 里面, 如: (?<=K).
前后缀逻辑组件
[注] 下面是前后缀逻辑实现时用到的字符, 不能直接使用, 这样拆开写只是为了容易理解! 切记不可直接使用!
| 符号 | 描述 |
|---|---|
| ?< | 前缀描述符, 必须写在 "被描述字符或字符组" 的 前面 |
| ? | 后缀描述符, 必须写在 "被描述字符或字符组" 的 后面 |
| = | 是 |
| ! | 不是 |
前缀逻辑 (前行断言)

| 符号 | 描述 |
|---|---|
| (?<=) | 前缀为 描述符 |
| (?<!) | 前缀不为 描述符 |
[注] 前缀描述符必须写在 "被描述字符或字符组" 的 前面 ! 切记 !
示例:
(?<=K)[0-9]{11}: 匹配以 'K' 为前缀的 11 位数字.
(?<!K)[0-9]{11}: 匹配不以 'K' 为前缀的 11 位数字.
后缀逻辑 (后行断言)
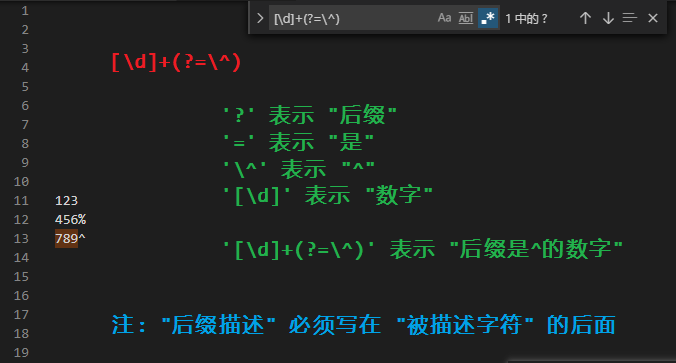
| 符号 | 描述 |
|---|---|
| (?=) | 后缀为 描述符 |
| (?!) | 后缀不为 描述符 |
[注] 后缀描述符必须写在 "被描述字符或字符组" 的 后面 ! 切记 !
示例:
[\d]{11}(?=K): 匹配以 'K' 为后缀的 11 位数字.
[\d]{11}(?!K): 匹配不以 'K' 为后缀的 11 位数字.
答案
A1: (?<=$)[\d.]+ 答案不唯一
A2: [\d.]+(?=$) 答案不唯一
修饰符
会修改正则表达式的匹配模式, 可以以任意顺序或组合使用, 先将要修饰的整个正则表达式前后加一个 / 字符, 然后在后面的 / 字符后面加修饰符.
| 标记 | 描述 |
|---|---|
| i | 不区分大小写: 将匹配设置为不区分大小写. |
| g | 全局搜索: 搜索整个输入字符串中的所有匹配. |
| m | 多行匹配: 会匹配输入字符串每一行. |
示例:
/(T|t)he/gi: 全局搜索, 不区分大小写, 正则:(T|t)he/.(at)/g: 全局搜索, 正则:.(at)/at(.)?$/gm:全局搜索, 多行匹配, 正则:at(.)?$
C# 中的正则表达式
- 全部匹配
1 | using System.Text.RegularExpressions; |
- 匹配第一项
1 | using System.Text.RegularExpressions; |