理解计算机中的字符编码
🌠前言
今天再一次体会到了 基础知识不扎实会带来无数的问题与困扰 这句话是多么地真实 ! ! 事情起因是我想巩固一下 SQL 知识, 于是用 SQL Developer 工具开始写 SQL, 但是当我用 SQL Developer 打开一个之前在 PL/SQL 上编辑的 SQL 文件的时候, 里面所有的中文全部乱码了 ! ! 我就知道我必须要解决 编码 这个困扰我许久的问题了. 于是上网搜索资料, 最后总结如下, 我使用了编码的发展顺序来组织文章结构 ( 大概, 或许, 应该, 差不多是这么个发展顺序吧, 哈哈 ! ), OK, 我们开始.
字符集 和 编码规则
有两件事必须在最开始就要点出, 这也是这篇文章的重心所在.
- 字符集和编码规则是完全不同的两种事物:
字符集: 为每一个字符分配一个唯一的 ID.
编码规则: 定义如何将之前定义的 ID 转换为计算机中的字节序列的一整套规则.
这里不需要特别明白, 只需要知道有这样一个区别即可, 后面根据实例来理解它们会更容易.
- 字符集和编码规则仅在讨论计算机存储时有效.
计算机基础
在计算机内部, 所有信息最终都是一个二进制值. 每一个二进制位 (bit) 有 0 和 1 两种状态, 因此八个二进制位就可以组合出 256 种状态, 这被称为一个字节 (byte). 也就是说, 从 0X00 到 0XFF 的一个字节一共可以用来表示 256 种不同的状态, 如果让每一个状态对应一个符号, 就是 256 个符号.
ASCII
于是美国就率先制定了一套字符编码, 来解决英语字符与二进制位之间的关系, 并做了统一规定. 这被称为 ASCII, 即 美国信息交换标准代码, 一直沿用至今.
由于 ASCII 提出的时候, 字符集和编码规则这两个概念尚未区分, 于是 ASCII 既表示字符集又表示编码规则. 不过为了好理解, 我们这里来一波强行解释! 上图!
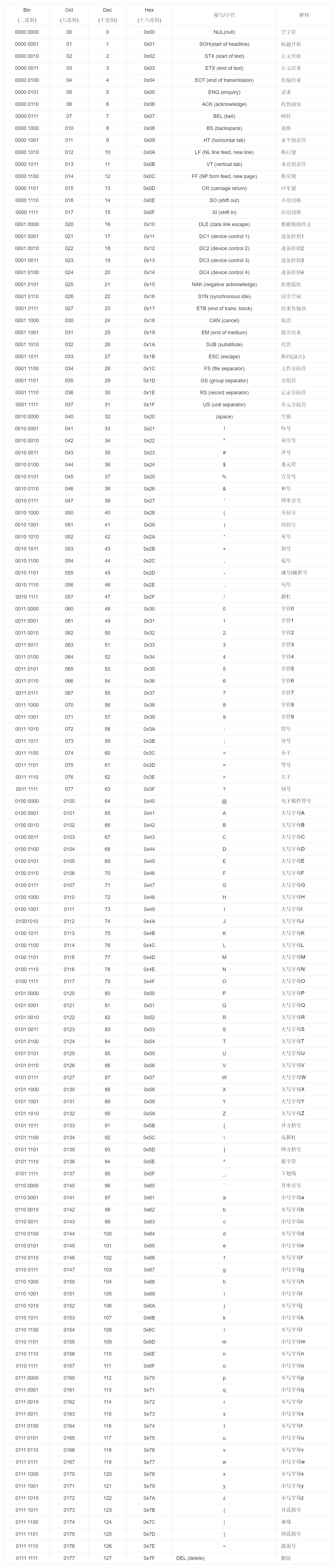
ASCII 字符集
上图中的 Bin 和 缩写/字符 这两列就是字符集, 一共规定了 128 个字符以及这 128 个字符的 ID.
字符集就只是负责这个工作, 即给每个要表示的字符分配一个 ID, 创建一种映射关系, 至于这个 ID 在计算机中怎么储存, 是用 1 个字节还是 2 个字节还是可变长度字节是不需要字符集去考虑的. 即使是仅仅只有 128 个字符的 ASCII 字符集, 我在电脑中就喜欢用 2 个字节表示, 我硬盘空间有的是, 我就喜欢 1 个字节表示字符, 另 1 个字节在旁边站岗, 谁又管的着呢? 虽然这很蠢!
ASCII 编码规则
- ① 每个字符都使用 1 个字节表示.
- ② 这个字节的首位始终为 0.
ASCII 字符集经过编码规则的限制之后, 在计算机中就表示为了: 0000.0000 到 0111.1111.
这样应该就有点明白字符集和编码规则的区别了吧. 其实当时那个年代 字符集 和 编码规则 这两个概念还没有明确建立, 因为没必要区分开, 默认情况下, 字符集所定义的 ID 的二进制形式就直接是编码规则, 但是随着时代的发展, 明确建立这两个概念就很有必要了. 比如后来提出的 Unicode 字符集, 在 2020 年 3 月的 ISO/IEC 10646:2020 版本中, 总共有 143924 个字符, 其中部分字符会占用 4 个字节, 总不能还是使用 字符集所定义的 ID 的二进制形式就直接是编码规则 这种简单的对应了吧, 因为这样的话所有的字符都要用 4 个字节, 原来只需 1 个字节的英文字母现在需要 4 个字节, 原来只需要 2 个字节的汉字现在也需要 4 个字节, 而且 Unicode 编码还在不断地补充进化, 所以这样实在是太浪费空间了! 我还要用硬盘存放珍贵的电影资源呢! 更大的影响是在网络传输方面, 原本只需传输 1 MB 的数据量, 现在却要传输 4 MB, 这太浪费带宽了!
[注] ASCII 是后面一切编码的基础, 因此即使字符编码不断发展, 发展后的它们也都会考虑到和 ASCII 的兼容性, 因此你会看到后面的编码都会做出一些相应的措施来兼容 ASCII.
扩展版 ASCII
随着计算机的普及, 计算机进入了欧洲国家, 但是 ASCII 中不包含其他语言的字符啊! 像希腊字母, 罗马字母等. 那么这些欧洲国家就很难受啊! 正好 ASCII 只使用了 1 个字节的后 7 位, 于是, 一些欧洲国家就决定, 利用 ASCII 编码规则中闲置的最高位编入新的符号 ( 你美国人不是才用了半个字节吗, 那好, 剩下的半个字节由我们来定义 ). 这样一来, 这些欧洲国家使用的编码体系, 就可以表示 256 个字符, 我们称之为 扩展版 ASCII.
扩展版 ASCII 字符集
扩展版 ASCII 字符集规定了 256 个字符. 其中 128 个字符直接沿用了 ASCII, 以达到兼容的目的, 剩下的 128 个字符是欧洲国家自己定义的字符. 当然由于每个国家语言不同, 对于这 128 个字符, 不同的国家自然有不同的定义, 那么肯定也会有它们独特的称呼, 但本质上它们都属于扩展版 ASCII 字符集🤣. (是不是感觉开始出现了混乱的味道? 嗯哼~) 但是不管怎样, 所有这些扩展版 ASCII 字符集中, 0 ~ 127 表示的符号是一样的, 不一样的只是 128 ~ 255 这些字符.
扩展版 ASCII 编码规则
- ① 每个字符使用 1 个字节表示.
于是扩展版 ASCII 字符集经过编码规则的限制之后, 在计算机中就表示为了: 0000.0000 到 1111.1111. ASCII 和扩展版 ASCII 两者之间互不冲突, 相安无事.
从扩展版 ASCII 开始, 这种命名就具有了表示一个大类的意味, 在这个大类下, 具体会细分成很多字符集, 比如, 意大利有意大利的扩展版 ASCII, 法国有法国的扩展版 ASCII, 瑞士有瑞士的扩展版 ASCII. 其中最优秀的字符集扩展方案是 ISO 8859-1, 通常称之为 Latin-1, Latin-1 利用 128 ~ 255 这 128 个二进制数, 包括了足够的附加字符集来涵盖基本的西欧语言, 同时在 0 ~ 127 的范围内兼容 ASCII 编码规则.
ANSI
之后, 计算机进入了亚洲国家, 亚洲国家使用的符号就更多了, 其中我国的汉字就接近十万个! 常用字也有四千多个. 由于前面的 ASCII 和扩展版 ASCII 的单字节字符集只能表示 256 种符号, 这对于我们博大精深的汉语来说是肯定不够的, 于是单字节不行, 就必须使用多字节. 于是就诞生了一系列的多字节字符集, 其中一类就叫做 ANSI 字符集.
ANSI 字符集是从 0X0000 定义到 0XFFFF, 理论上来说, 只要全部的字符都使用 2 个字节表示, 就可以包含 65536 个字符 (但是实际的编码规则不会这么简单直接), 这对于任何单个国家的字符需求来说, 都能基本满足了.
ANSI 字符集定义了要表示的字符以及对应的 ID, 但是并不意味着将这些字符编到计算机中的时候会遵守 字符集所定义的 ID 的二进制形式就直接是编码规则 的游戏规则. 就比如后面会提到的 GB 2312 字符集使用的 EUC-CN 编码规则, 半角字符只占 1 个字节, 汉字和全角字符才会占用 2 个字节 (是不是已经开始有点晕了😵).
[注] 网络上有人说 ANSI 字符集是 ASCII 字符集 的扩展, 我想他应该是把我前面所提到的 ASCII 字符集和 ASCII 扩展字符集都统称为了 ASCII 字符集, 于是得出了他的这个结论. 我认为我的说法和他的说法没有绝对的谁对谁错, 只是不同的两种理解. 在现在这个信息交流如此便利的时代, 我也希望大家在非原则问题上不要过于较真. 不过本文中一直采用的是我自己的看法, 即 ASCII 字符集和 ASCII 扩展字符集不统称为 ASCII 字符集. 接下来让我们回到正题.
ANSI 字符集
ANSI 字符集中包含的字符具体是什么不好说, 因为不同国家的 ANSI 字符集包含的字符是不一样的, 和当时的 ASCII 扩展字符集的发展轨迹相同, 对于 ANSI 字符集, 不同的亚洲国家同样设计了他们各自的字符集 (这里我终于搜索到这些细分的 ANSI 字符集所对应的名字了 😂), 比如日本的 ANSI 字符集叫做 JIS X 0208, 韩国的叫做 KS X 1001, 我国的 ANSI 字符集叫做 GB 2312, 释义为: 信息处理交换用汉字编码字符集基本集. 下面简单说一下 GB 2312 中所规定的字符集内容.
GB 2312 共收录 6763 个汉字, 其中一级汉字 3755 个, 二级汉字 3008 个, 同时收录了包括拉丁字母, 希腊字母, 日文平假名及片假名字母, 俄语西里尔字母在内的 682 个字符.
GB 2312 的出现, 基本满足了汉字的计算机处理需要, 它所收录的汉字已经覆盖中国大陆 99.75% 的使用频率.
ANSI 编码规则
- ① 不同的 ANSI 字符集会规定其独特的编码规则.
这个还真的都不一样, 但是也都是有基准的. 比如我国的 GB 2312 字符集使用的 ANSI 编码规则叫做 EUC-CN, 日本的 JIS X 0208 字符集在 Windows 上使用的 ANSI 编码规则叫做 EUC-JP, 韩国的 KS X 1001 字符集使用的 ANSI 编码规则叫做 EUC-KR. 这些编码规则都是 EUC 类的编码规则.
是不是头都大了? 😂 只要知道不同的 ANSI 字符集 会采用一些不同的编码规则即可.
总结一下, ANSI 是一类字符集的统称, 不同的国家有其自己的 ANSI 字符集, 不同的字符集也会对应不同的编码规则, 同样编码规则也都有各自的名称.
有人可能会问, 后面不是会出现 Unicode 这种全球统一的字符集吗, 那为什么还要继续使用和发展 ASNI 这种国家之间无法兼容的字符集呢? 这个问题呢我后面会解答.
Unicode
ASNI 出现之后, 各个国家的字符需求基本都解决了, 但是因为每个国家制定了他们各自的字符集和对应的编码方案, 所以各个国家之间的字符集不通用, 于是制定一套全球统一编码的呼声越加强烈! 最后 ISO 即 国际标准化组织 实在看不下去了, 为了解决不同国家 ANSI 的冲突问题, ISO 就制定了一套全球统一编码, 即 Unicode.
Unicode 时代的时候, 字符集和编码规则就已经很明确了, Unicode 仅仅只是一种字符集. 其中定义了全世界所有符号的唯一标识 ID, 并且一直在不断地修订. 2020 年 3 月的 ISO/IEC 10646:2020 标准中, 已经包含了 143924 个字符.
如果使用简单的 字符集所定义的 ID 的二进制形式就直接是编码规则 的方法来存储 Unicode 字符集, 将会造成极大的浪费, 于是为了解决 Unicode 这个庞大字符集的存储和网络传输问题, 对应 Unicode 字符集的编码规则就出现了. 其中最常用的就是 UTF-8 编码规则了. 其他的编码规则还有 UTF-16 BE, (Big-Endian 大端序) UTF-16 LE (Little-Endian 小端序), UTF-32, UTF-7, Punycode, CESU-8, SCSU, GB18030 等等.
对于之前说的为什么还要继续使用 ANSI 字符集的原因是, Unicode 下的各种编码规则, 对于常用汉字, 基本上都是占用 3 个字节, 生僻汉字可能占用到 6 个字节. 对于 GB2312 和 GBK 来讲, UTF-8 无疑造成了浪费, 所以, UTF-8 可以说是对英文友好, 但对中文不友好的一种编码方式. 所以在中文界, GB2312 与 GBK 依旧有自己的市场. 但是按照目前的趋势来看, 硬盘都是白菜价, 电脑性能也已经足够无视这点性能的消耗了. 所以推荐所有的网页使用统一编码: UTF-8.
其中关于 UTF-8, GB18030 内部的具体编码规则就不展开说了 (其实我也不会, 哈哈), 有兴趣的可以自己搜索资料, 维基百科就是一个比较好的选择.
总结
- 美国人为了表示日常用的字符, 制定了 ASCII 字符集.
- 欧洲人为了表示日常用的字符, 扩充了 ASCII 字符集.
- 中国人为了表示常用简体汉字, 制定了 GB2312 字符集.
- 中国人为了表示生僻汉字和繁体字, 扩充 GB2312 字符集为 GBK 字符集.
- ISO 为了统一全世界的字符, 制定了全球字符集 Unicode, 目标为包含世界上全部的字符.
- 为了方便 Unicode 的传输和存储, 制定了 UTF-8, UTF-16 等一系列编码规则.
💖 举例
现在在程序编码过程中, 你的一个变量被赋值了这样一个字符串, \u5730\u7403\u002c\u0020\u7531\u6211\u6765\u5b88\u62a4\u0021, 考虑下面几个问题:
- 这一串字符串使用了什么字符集?
- 这一串字符串使用了什么编码规则?
- 使用什么规则对其解码? 字符集映射, 还是编码规则?
解析:
这只是一串字符串, 我们并没有在讨论它的计算机存储方式, 因此字符集和编码规则统统无意义. 如果此时此刻这串字符串储存在计算机中, 此处的讨论才会有意义, 字符集及其编码规则全都是在讨论计算机如何存储字符的, 如果不讨论存储便没有意义.
对其解码需要使用 Unicode 字符集映射, 原因就是因为这是 Unicode 中对字符定义的 ID, ID 为 \u5730 的字符是 地, ID 为 \u7403 的字符是 球, 后面的依次是: ,, , 由, 我, 来, 守, 护, !.
参考链接
字符编码笔记: ASCII, Unicode 和 UTF-8
网页编码就是那点事
Unicode 和 UTF-8 有什么区别
字符集和编码方式的区别
ASCII 码和 ANSI 码的区别
从 ASCII 到 UTF-8 字符集到底是什么
ASCII 码 和 Unicode 码是什么关系