Git 和 Fork
推荐一个 Git 的学习网站, 以游戏的方式来学习 Git. 点我
用户信息 (Windows)
Windows 系统的用户文件夹下有一个 .gitconfig 文件, 这个文件中存储了 git 的全局设置, 包括提交时的用户名以及邮件地址, 还可以设置一些 git 长命令的别名, 用于简化操作.
Git 版本库中每一个 commit 节点都有一个提交者, 这个提交者默认就是用户文件夹下 .gitconfig 文件中配置的用户名和邮件地址. 但是如果不同的仓库需要不同的提交者怎么办呢?
Git 版本库在所使用的提交者信息有 3 个层级, 分别是: 仓库级 local, 全局级 global, 系统级 system.
系统级用户信息
系统级的配置文件是 Git安装目录/etc/gitconfig 文件, 这个文件中的配置优先级最低, 会被另外两个配置文件中的配置所覆盖.
全局级用户信息
全局级的配置文件是 用户文件夹/.gitconfig 文件, 这是一个隐藏文件, 其中最重要的设置就是保存了默认的用户信息. 由于这里保存的是默认信息, 因此除非配置错误, 否则不要修改 .gitconfig 中的配置.
仓库级用户信息
仓库级的配置文件是 仓库文件夹/.get/config 文件. 只要在这个文件中给你再次配置一个 [user] 信息便可以实现不同的仓库使用不同的提交者信息.
Git 版本控制结构
Git 在实现版本控制时的结构如下图:
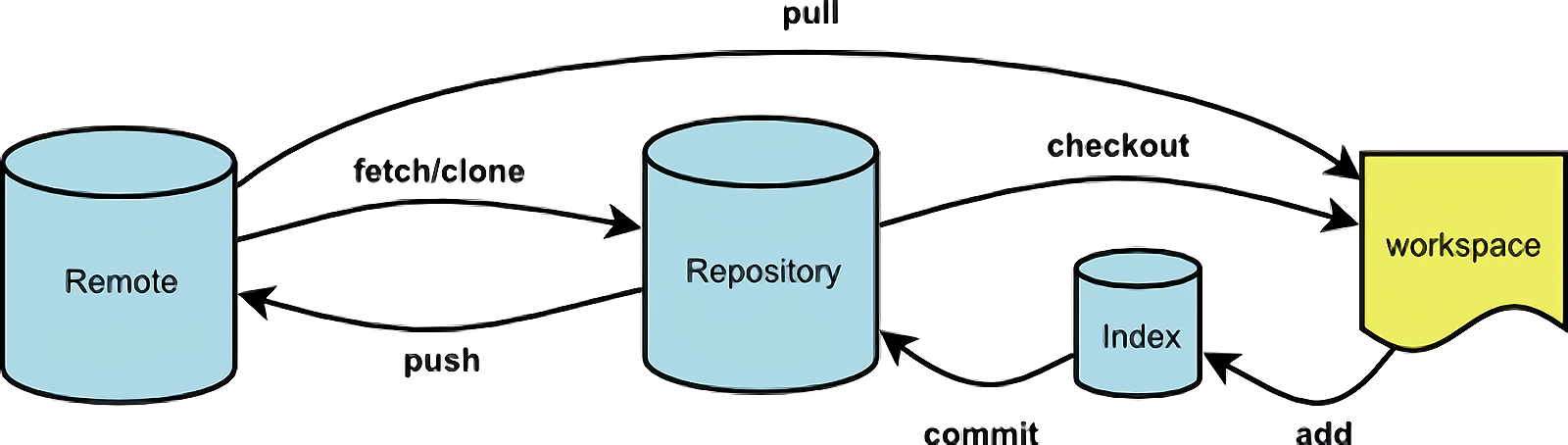
其中的 Repository, Index, Workspace 为本地文件, Remote 是远程文件.
在克隆远程仓库之后的整个文件夹就是我们的仓库目录, 其中除了 .git 文件夹以外的文件及文件夹称为工作区, 默认情况下, 同目录下的 .git 文件夹保存了这个仓库的版本提交信息.
图中各个图标的解释:
- workspace: 工作区, 我们实质的项目文件.
- Repository: 本地的版本控制信息. 位于 .git 文件夹中, 其中保存了从开始进行版本控制以来所有的提交记录, 后面的暂存区也在这个文件夹中.
- Index: 暂存区, 我们所有改动在提交之前都必须先放到暂存区中. 也在 .git 文件夹中. Fork 软件中的 Stage 命令就是将改动保存到暂存区.
- Remote: 远程服务器上的文件.
branch-name 和 HEAD
branch-name 和 HEAD 都不是提交信息, 这两个都只是一个游标, 它们指向特定的节点.
HEAD 也称作 current branch, 是一个指向当前工作区所处位置的游标, 主要由 checkout 命令控制, HEAD 不仅可以指向分支名, 也可以直接指向某个提交节点.
在签出本地仓库中的一个分支时, HEAD 便会指向这个分支名, 比如签出了 bugFix 分支, 则: HEAD->bugFix->bugFix-commit.
在签出远程仓库中的一个分支时, HEAD 会变成分离状态, 比如签出了 bugFix 分支, 则: HEAD->bugFix-commit. 这样是为了保证用户必须在自己新建的本地分支上工作, 不能直接在远程分支上进行修改和提交, 生成 commit 节点.
Git, GitHub 和 GitLab
Git 是一个分布式版本控制工具, 一个仓库所有的提交记录全部保存在 .git 文件夹中. 随着项目的开发, .git 文件夹的体积会越来越大.
GitHub 是一个注重点为 开源 的代码托管网站, 他的特点就是仅支持 Git 作为版本控制工具, 并且提供了很多 Git 相关的便利操作, GitHub 和 Git 是完全不同的两个事物. 由于 GitHub 的注重点为开源, 因为对于开发闭源软件的团队而言, GitHub 就不适用了.
GitLab 是一个面向企业团队的代码托管网站, 和 GitHub 非常相似, 最大的不同就是 GitLab 上的仓库是隐私的(现在 GitHub 也可以创建私有仓库了😂), 而且提供了更好的隐私权限管理工具, 适合公司的内部团队使用.
Git 命令
git init: 创建一个初始的 git 版本库 (git 仓库).git add: 将当前的改动提交至暂存区 (暂存区一般称为: stage 或 index).git commit: 提交到本地版本库, 提交后会在本地版本库中会新增一个节点.git branch new-branch-name: 在当前位置新建一个分支, 但是并不会立即签出到新的分支上.git branch new-branch-name HEAD-position: 在指定位置新建一个分支, 不会立即签出到新的分支上.git branch -f branch-name HEAD-position: 强制修改特定分支到指定的 HEAD 位置. 不会修改节点信息, 只会修改分支名 (分支名是一个游标).git checkout branch-name: 签出到特定分支上, 修改 HEAD 指向指定的分支名.git checkout -b new-branch-name: 在当前位置新建一个分支, 并签出到这个新分支上.git checkout -b new-branch-name HEAD-position: 在指定的位置新建一个分支, 并签出到这个新分支上.git merge branch-name: 将特定分支归并到当前分支中, 合并分支的一种方式, 提交树中会有明显的合并痕迹. 归并模式git rebase branch-name: 将当前分支移动到特定分支中, 合并分支的另一种方式, 由于是直接移动, 所以被合并的分支会消失. 移动模式git rebase branch-name-a branch-name-b: 将分支 b 移动到分支 a 中.git reset branch-name^: 将当前分支撤销一步提交, 具有 3 种撤销方式. 仅对本地有效 [推荐使用]git revert branch-name: 将当前分支撤销一步提交. 本地和远程都有效 [不推荐使用]
相对引用 (HEAD-position)
git checkout branch-name^/~number: 相对引用.git checkout main^: 将 HEAD 修改为 main 分支回退 1 次后的节点.git checkout bugFix~4: 将 HEAD 修改为 bugFix 分支回退 4 次后的节点.git checkout HEAD^: 将 HEAD 回退 1 次. HEAD 必须大写git checkout HEAD~4: 将 HEAD 回退 4 次.
图形客户端 Fork
用户信息设置
在仓库名的右侧有一个设置按钮, 可以对自己提交时的用户信息进行设置.
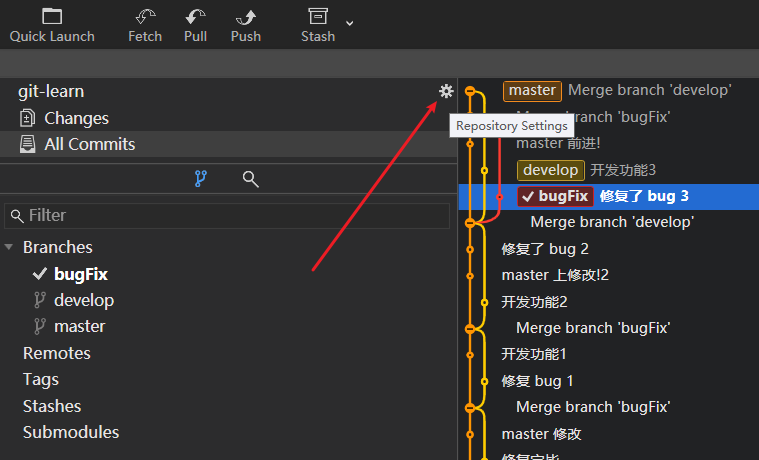
勾选 Use global git credentials 时会使用全局级设置, 在需要单独设置用户信息时, 需要取消勾选并设置自己的用户信息.
添加本地仓库
如果本地已经有仓库了, 可以将仓库直接添加到 Fork 中. 点击 File->New Tab, 打开一个新的标签页, 或者直接点击标签栏最右侧的 + 号也可以创建新 Tab 页.
将自己本地的仓库文件夹 (内部有一个 .git 文件夹的文件夹) 直接拖到 Repositories 处即可添加本地仓库. 另外还可以在 Repositories 处, 右键=>新建文件夹, 进行仓库的整理和归类. 双击添加的仓库即可打开仓库.
多工作区
在 Fork 中每一个标签页 (Tab) 就是一个仓库的信息, 可以在一个窗口中打开多个仓库, 这样上方就会同时出现多个 Tab 页.

但是不同的工作内容 (修复 Bug; 新增功能; 修改美术或音频资源) 可能需要用到不同的仓库, 不同的分支, 此时多标签页已经无法满足要求了.
这个时候可以使用多工作区来解决. 在软件的右上角有一个 Workspaces 按钮可以对工作区进行设置. 这个按钮上显示的文字是当前工作区的名称.

可以理解为一个窗口一个工作区, 不同的工作区中可以放不同的标签页, 并且可以很方便的来回切换. 具体的自己去配置一下试试吧.
添加远程仓库
在仓库的下方有 Branches 和 Remotes, Branches 里面的是本地仓库的分支情况, Remotes 则是远程仓库中的分支情况.
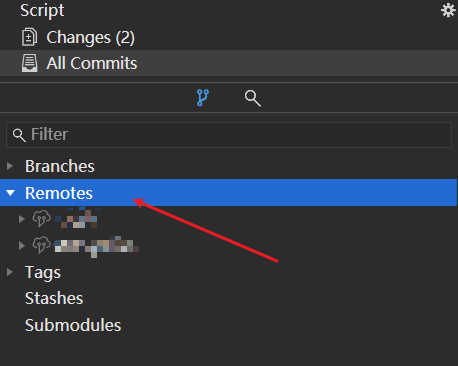
Remotes 中可以配置多个远端仓库, 虽然只能同时引用其中的一个, 但是可以随时修改引用哪一个仓库. 这个引用 git 中叫做追踪关系(tracking).
在 Remotes 上右键, Add New Remote, 填入远程仓库的名称以及网络地址即可.
本地的版本库信息 (也就是提交记录) 保存在本地仓库的 .git 文件夹内, 同样远端仓库的版本库信息保存在远端服务器的 .git 文件夹内. 添加远端服务器之后需要使用 Fetch 命令来拉取远程仓库中的版本信息, 拉取完之后就可以展开看到目前远端仓库中所有的分支了, 没有拉取的时候是没有左侧的三角号的, 也不能点击. 后面会说明 Fetch 命令, 当然你可以现在就跳转: Fetch 命令
Quick Lunch
说一下上方的几个按钮, 首先是 Quick Launch, 这是一个快速操作入口, 点击后会弹出一个窗口, 里面有很多常用的操作可以快速执行, 找不到需要的操作时可以进行搜索.
Fetch
场景 1: 我们在刚来公司的时候克隆 (clone) 了远端仓库的所有内容, 此时我们本地仓库和远程仓库是一模一样的, 然后我们找到需要工作的分支, 新建分支开始工作, 工作了一周之后, 我们本地的 .git 版本库中新增了很多我们自己的提交, 但是你会发现整个的提交树中并没有这一周内其他人的提交情况, 因为其他人的提交情况全部保存在他们自己的电脑上或者他们 push 到了远端的 .git 文件夹内.
场景 2: 我们在 Fork 上新加了一个远程仓库, 但是这个仓库的提交信息却没有任何显示, 怎么都找不到, 明明远程是有提交信息的.
这时候就需要使用 fetch 了, 这个命令可以将远程仓库中的提交记录拉取到本地, 这样我们也就可以看到其他人的工作情况了. 在 Fork 软件中点击 Fetch, 选择要拉取哪个仓库的信息, 之后拉取即可.
fetch 命令完成了很重要的两步:
- 从远程仓库下载本地仓库中缺失的提交记录
- 更新提交树中的远程分支游标
[注]
Fork 的默认配置中会自动进行 Fetch, 每次在打开一个标签页或者切换标签页的时候都会自动 Fetch, 我这里是选择了关闭这个自动 Fetch, 因为他让我失去了一部分掌控感, 还是自己需要 Fetch 的时候手动去 Fetch 一下更有实感! 😂
![自动-Fetch]()
fetch 只是拉取一遍提交记录, 也就是软件界面中间部分的提交树信息, 所以一般在需要查看目前仓库的提交情况时使用这个命令, 另外因为 fetch 不会对文件做任何的改动, 所以基本上来说这个按钮可以随便点. 当设置了多个远程仓库的时候, 点击 fetch 需要选择拉取的仓库.
Pull
pull 也是拉取远端服务器的数据, 和 fetch 不同的是, pull 在拉取之后会将刚刚拉取的节点合并到当前签出的分支上. 等于先执行 fetch 命令, 之后执行 merge 命令.
应用场景: 我们签出了远程分支 origin/feature, 一周后在本地进行了一次提交, 但是在这一周内 origin/feature 分支在远程仓库上进行了新的提交, 此时就需要先拉取远程仓库的提交, 之后再将刚刚拉取的远程节点合并到我们的本地分支上. 要实现这个效果可以先执行 fetch 命令, 之后执行 merge 或者 rebase 命令, 也可以直接执行 pull 命令.
| 命令 | 等效命令 |
|---|---|
| pull | fetch + merge |
| pull --rebase | fetch + rebase |
Push
Push 和 Pull 相反, Push 是将本地 .git 文件夹中的提交记录上传到远程服务器中. 比如要修改一个 Bug, 我们先找到 Bug 存在的分支, 之后新建一个分支开始工作, 工作过程中产生了很多的提交, 这些新的提交信息我们在本地都是可以清楚的看到的, 但是远程服务器中是没有这些提交信息的, 甚至连我们新建的那个分支都没有... 此时我们就可以使用 Push 命令将我们的工作情况上传上去. 第一次提交时由于我们是新建的分支, 远程版本库是没有的, 因此提交的时候软件会默认在远程版本库上新建一条同名的分支, 这是 Git 的默认操作, 我们不需要进行额外操作. 此时他人使用 Fetch 命令就可以看到我们的提交记录了.
push 默认上传的时当前签出的分支, 可以使用参数将指定的分支进行上传.
push remote-repository-name branch-name: 将本地的 branch-name 分支上传到远程的 branch-name 分支. 此时本地分支和远程分支同名.push remote-repository-name local-branch-name:remote-branch-name: 将本地的 local-branch-name 分支上传到远程的 remote-branch-name 分支. 此时本地分支和远程分支不同名, 并且 local-branch-name 也可以直接写一个节点. 记得本地位置和远程分支之间必须使用冒号 : 连接.push remote-repository-name :remote-branch-name: 本地分支参数省略时, 此命令的效果是删除远程的 remote-branch-name 分支.
checkout
Checkout 是签出操作, 将当前仓库中的所有文件变成指定分支中的样子. 一旦签出, 我们的工作区就和分支中的完全相同, 因此在切换分支的时候必须对当前分支上所作的变动全部保存或者直接提交.
进阶操作
cherry-pick
cherry-pick 命令可以选择性地将提交树上其他分支的提交记录复制过来追加到 HEAD 上, 需要知道节点的 hash 值.
cherry-pick node1-hash [node2-hash] [node3-hash] : 将节点 1 2 3 转移到当前分支上.
[注] 未合并的节点所作的改变将被丢弃.
在命令行中 cherry-pick 是这样使用的, 但是在 Fork 软件中怎么使用呢?
场景想象: 我们在自己的工作分支上工作, 其中做了 5 次提交: a, b c d e, 这些提交中的 a, c, e 是真正有效的提交, 虽然 b, d 两次提交也作出了修改, 但是 b 中的修改全部都是 Debug 时用的测试代码, d 中的提交也全部都是 Print 时输出信息用的代码. 这些代码不需要合并到主分支上, 就是说这两次提交需要舍弃, 那么此时就可以使用 cherry-pick 了.
首先将工作分支上的改动全部提交, 之后签出到要合并的主分支上, 如 develop 分支, 之后同时选中需要合并的 a, c, e 节点, 右键, 选择Cherry-pick... 就可以将 a, c, e 复制到主分支上了. 由于 cherry-pick 是复制操, 所以我们自己的工作分支还是保持不变的, 后面可以选择是否进行删除操作.
rebase interactive
命令格式: git rebase -i HEAD-position
直译为: 交互式 rebase, 使用此命令会打开 UI 界面, 对指定范围的节点进行自定义操作, 下图中是所有可以做的操作.
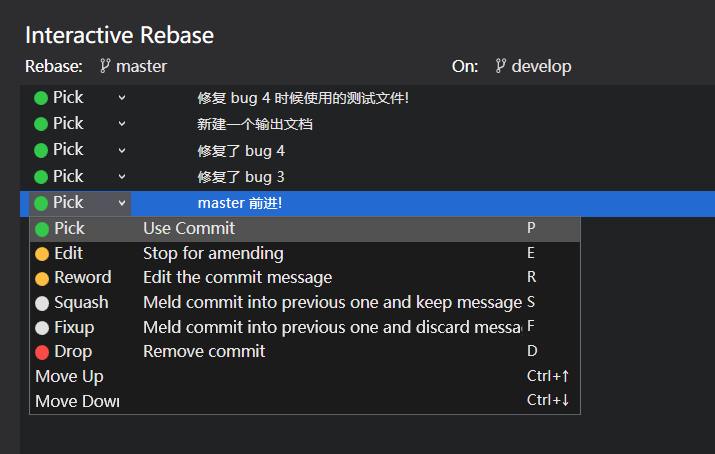
和 cherry-pick 一样, 被舍弃 (Drop) 的节点中所做的改变也会被舍弃.
git rebase -i HEAD~4 : 对当前节点以及前面的 3 个节点 (共 4 个节点) 进行自定义操作. 由于是移动模式, 所以被修改的节点会在原分支消失, 直接被移动到了主分支.
tags && describe
Git 中有一个标签功能 (里程碑功能). 标签(里程碑)的作用就是一个不可变的永久指针, 它指向最初定义它的位置. 当发布了一个全新版本, 或者进行了一个大型重构等都可以使用标签对那次重大提交打一个 "标记".
git tag tag-name node-name : 在指定的节点上新建一个标签(里程碑).
标签(里程碑)主要是用来定位, 可以使用 git describe 命令来进行定位, 命令返回的格式为: [tag-name]-[step-number]-[position-hash].
git describe: 距离当前最近的里程碑到当前位置的提交次数. 假设当前节点 hash 为 c2, 是 v1 版本提交了 12 次后的结果, 则此命令返回: v1-12-c2.git describe main: 距离 main 分支最近的里程碑到 main 分支的提交次数. 假设 main 分支 hash 为 c3, 是 v2 版本提交了 5 次后的结果, 则此命令返回: v2-5-c3.git describe develop: 距离 develop 分支最近的里程碑到 develop 分支的提交次数. 假设 develop 分支 hash 为 c6, 是 v4 版本提交了 7 次后的结果, 则此命令返回: v4-7-c6.
问题处理
如何消除冗余提交 Squash && Reset
情景: 在工作时由于进行了多次不必要的提交, 所以提交树上产生了很多冗余的提交, 这对于强迫症来讲是坚决不能忍受的. 比如下图中在编写 Git 博客的时候产生了多次添加图片的冗余提交.
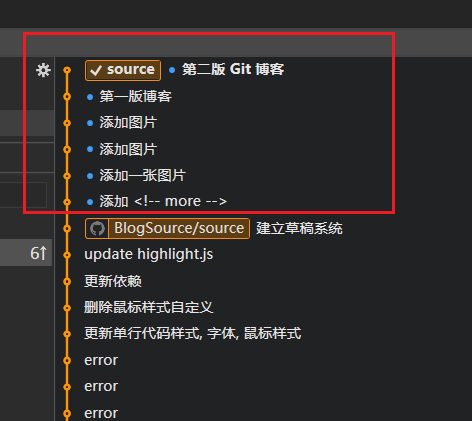
- 方案1: 仅适应于本地仓库中的冗余提交, 一旦提交已经 Push 到了服务器上就不推荐使用这个方案了, 虽然理论上行得通, 但是容易出现冲突. 这个方案的想法是使用 Fork 上的 Squash (直译: 压扁) 来压缩提交数量. 首先将目前工作区所有的改动保存并提交, 之后同时选中所有需要压缩的节点 (顺序选择, 不要挑着选, 不然可能会有冲突), 右键, 选择: Squash into Parent..., 在弹出的窗口中会出现操作的详情, 窗口左下角默认会勾选备份, 确认无误后就可以点击右下方 Rebase 压缩提交记录了.
[注] 这个操作需要对操作树中的节点具有很强的掌控感, 节点选择多了一个都会导致后期合并起来出问题, 强烈建议使用此操作之前找个空仓库多练习几次.
- 方案2: 仅适应于本地或者 Push 到服务器但是还没有合并的情况. 应该说任何已经合并到主分支的提交都不能由非管理员进行回退! 方案 2 的想法就是使用 Reset 回退提交. Reset 的回退有 3 种方式, 每个对应的参数以及效果见下图.
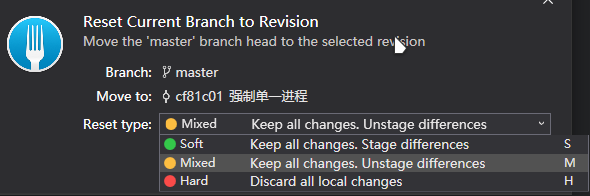
使用 Reset 回退之后 Push 到远端时默认会报错, 因为将一个旧的提交去覆盖新的提交肯定不行, 此时就需要使用 强制提交, 强制覆盖掉远端的提交记录.
如何避免产生冗余提交 commit --amend
第一种方案:
git commit –amend命令在提交时不会生成新的提交记录, 而是直接修改当前 HEAD 指向的节点, 这样就不会产生冗余的提交记录了, 但是 Fork 软件中好像没有这个功能. (我没有找到)第二种方案: 使用 Reset 命令先消除之前的无意义提交再重新提交, 回退时使用 Soft 方式即可. 完全掌控的情况下使用默认的 Mixed 方式也可以.
第三种方案: 使用 Stash 功能.(推荐)
- 适用情景: 当前我们在 A 分支上正在非常聚精会神加高度专注地实现一个屌炸天的模块, 思如泉涌, 简直键盘如飞地在编写代码~~~~然后这时, 收到一封邮件反馈出一个 bug, 非常严重, 必须马上解决, 优先级为 0 !!! 于是, 我们需要立即签出到 B 分支上 checkout 新的分支进行工作, 但是我们那个屌炸天的功能还没完成怎么办? 如果直接提交的话就会出现一个无意义的提交啊!! 咋整??
- 使用 stash 命令. Stash 命令用来保存当前工作进度, 会把暂存区和工作区的改动保存起来, 在提交树中会显示为一个抽屉(?或者箱子?), 不会生成 commit 节点.
如何修改之前提交的同时避免产生冗余提交
场景: 当前在工作分支上有 3 次提交: a, b, c, 其中 b 提交仅仅只是提交了一个美术素材, 但是现在需要修改这个美术素材的分辨率, 怎么办? 虽然可以直接在当前位置修改然后再创建一个提交 d, 但是这样提交就乱套了.
第一种方案: 使用
rebase -i来调整 a, b, c 的提交顺序为: a, c, b, 之后使用commit --amend修改 b 提交, 最后再次使用rebase -i把提交顺序换回去. 但是这个方案中 rebase 很容易产生冲突, 所以弃用.第二种方案: 首先使用
cherry-pick将 b 单独取出来到一个新分支上, 之后在新分支上对 b 进行修改, 提交后为 b2, 然后将 b2, c 这两个提交cherry-pick到另一个新分支上, 之后使用这个新分支继续工作, 这样可以保证不会产生冲突. 最后那两个旧分支可以删除.
使用 merge 还是 rebase
先看一下 rebase 和 merge 相比时, rebase 的优缺点:
rebase 的优点: rebase 使提交树变得很干净, 所有的提交都在一条线上, 不会保留工作时的分支记录.
rebase 的缺点: rebase 修改了提交树的历史, 比如, commit A 可以被 rebase 到 B 之后, 从提交树中看的话 A 中的工作是在 B 之后进行的, 但是实际上是在 B 之前.
因此如果没有这方面的规定的话, 使用 merge 还是 rebase 取决于个人爱好, 如果你喜欢保留所有的提交历史, 这样从提交树中看来浏览整个项目的发展历程, 那么你自然需要使用 merge, 如果你不喜欢那些历史性的分支, 而是喜欢看到一颗非常干净的提交树, 那么你自然需要使用 rebase. 这东西仁者见仁, 智者见智.
如何有效避免 .git 文件体积增大
首先最重要的就是必须设置 .gitignore 文件, 这个是提交前必做的事项, 项目中全部的临时文件都不能上传到 Git 上, 其他的就是一句话概括: 禁止提交大文件!
当然这也太笼统了, 哈哈!
Git 最害怕的就是无法进行内容修改比对的文件, 比如图片, 音频文件, 这些文件一旦修改了, Git 只能重新保存一份新的数据, 无法像文本文件, 代码文件那样仅保存改动信息, 因此这些文件如果提交到了 Git 上则需要确保不能进行频繁修改. 规避掉这一点就能有效避免 .git 文件夹体积过大.
如何让 Git 识别文件名称的大小写变化
Git 默认不区分文件名大小变化.
首先我们创建一个文件叫 readme.txt, 编辑内容, 之后提交, 推送到远程仓库.
然后我们在本地修改文件名为 Readme.txt, 之后再次提交, 但是此时会发现 Git 检测不到任何变化.
原因是 Git 默认对于文件名大小写是不敏感的, 所以当我们仅修改了文件名的大小写时, Git 并没有检测到任何改动.
解决方案: 在仓库目录中打开 Git 终端, 输入 git config core.ignorecase false, 回车即可.
执行完之后在仓库级别的 (不明白看文章开头) 配置文件中就会多一行配置
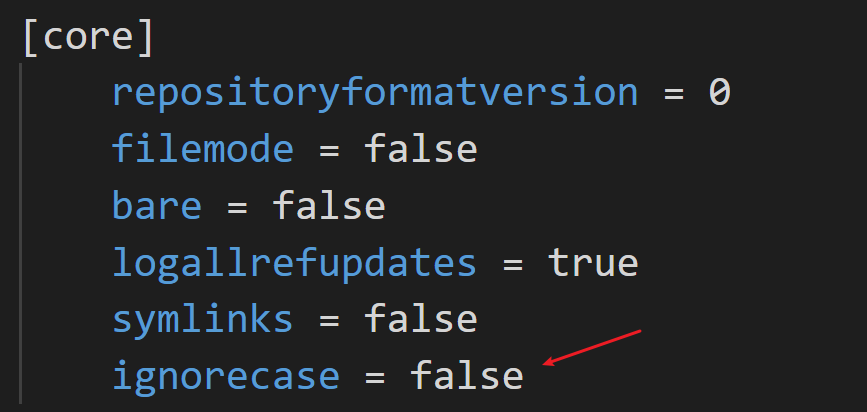
这样 Git 就可以不会再忽略大小写改动了.
为什么 Git 中文件的修改纪录会发生跳跃 ? 为什么本次的修改不是以上次的结果为基准 ?
一句话描述就是发生了舍弃操作, 把一部分修改舍弃了
进行变基或者合并操作时, 修改的内容产生了冲突, 在解决冲突的时候直接舍弃掉了某一方的修改, 这样查看修改记录时就会发现出现了跳跃
为什么文件中会残留冲突描述文本 ?
这 TMD 绝对是某些人用了什么诡异的操作, 没有按照正规的变基流程进行变基, 怒!!!
已查明原因, 请移步 这里 查看!
如何一键删除本地全部冗余分支 ?
git branch | grep -v "$(git branch --show-current)" | xargs git branch -d